前言
最近在项目里遇到了一点问题:某个里程碑因为git上merge失误的关系,不小心把下个里程碑的代码跟混进去了。由于缺乏有效的检查,加上QA童鞋回归时并没有测试某些极端的情况,在线上环境出了点问题,最后不得不重新发版解决。
痛定思痛,博主这边打算找些自动化的检查机制来避免以后再出现这种问题。
我们这边版本管理工具用的是Redmine,其实我们组里一直都有在commit信息上带上相关单号的好习惯(如:[#000000]xxxxxxx),不过一般只有进行codeReview的时候才会用到
考虑到最近项目迁移到了gitlab上,在某些特殊的时间能够触发webhook调用一些特定的url,博主决定自己搭一个nodejs服务器,在有push至gitlab的时候,对其commit的信息进行检查
流程
获取commit信息
当有push推送至gitlab服务器时,会触发gitlab的webhook中的Push events,具体的官方doc如下:
https://docs.gitlab.com/ee/user/project/integrations/webhooks.html#push-events
根据doc可以看到,请求的body中会通过json格式带上一些我们感兴趣的信息
值得注意的是,commits字段虽然有commit相关的信息,但是由于性能的缘故,只会有前20条相关的记录,而total_commits_count字段则会提供完整的commit数量
这该如何是好,总不能说当我们一次push太多commit去服务器的时候校验就失效了吧
考虑到像develop与master分支一般都会有上百次commit一口气push上来,这个问题还是不容忽视的
在参考了Jenkins构建项目时,其实是clone了一份代码至本地仓库来进行操作之后,博主也决定效仿:
决定在nodejs服务上也clone一份本地仓库,当发生push时通过pull指令更新,最终使用log指令来获取完整的commit信息
值得注意的是,这里为了获取正确的git log顺序,使用了–topo-order拓扑排序的参数(这里主要为了解决merge之后git log直接拉取数据的话,前几条并不一定是最新在当前分支上的修改的问题,说实话参数的doc介绍没看的太懂)
流程设计
流程图如下: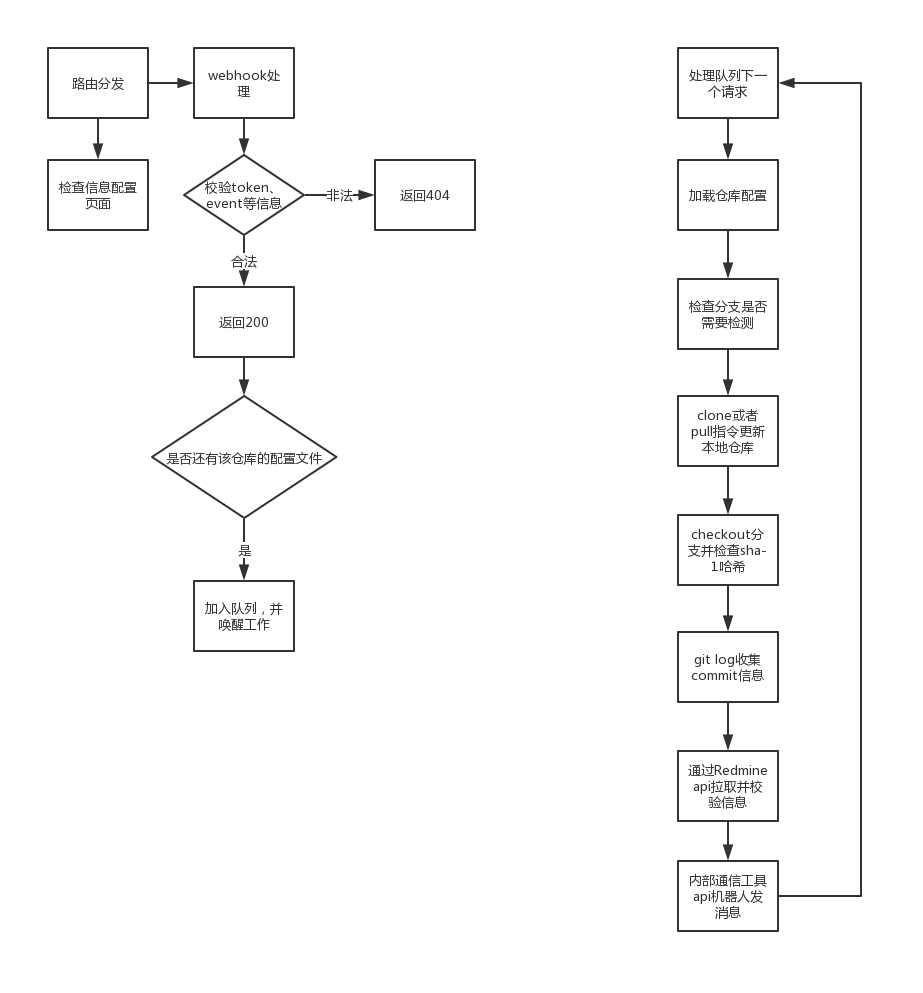
这里把实际检查工作放到一个队列中依次执行的原因主要是:
- 检查工作中包含多项异步处理(如:读取文件、更新代码、请求Redmine api数据)会比较耗时,此处应该尽快回复gitlab的webhook,避免webhook以为调用失败再次请求
- 由于使用本地仓库获取log日志的缘故,多个检查工作同时执行相关git指令可能会导致本地仓库出问题
相关代码
仓库文件编辑工具
1 | const fs = require("fs"); |
webhook校验代码
1 | const http = require("http"); |