LayoutInflater是一个我们在Android编程中经常使用到的用于生成解析布局文件的类,在这篇博客中我们将探索LayoutInflater的相关知识。
获取LayoutInflater实例
想要使用LayoutInflater,我们必须先获取它的实例,在Android中我们有如下两种方法:
1 | // 方法一 |
其实方法二只是方法一的包装而已,不过通常博主都会使用方法二,因为比较方便:
1 | public static LayoutInflater from(Context context) { |
LayoutInflater使用
在获取了LayoutInflater的实例后,我们可以使用它来解析我们的布局了。在LayoutInflater中给出的解析函数有如下四种重载:
1 | // 布局索引号,父View |
LayoutInflater源码
所有函数均返回一个View,由于前三项重载函数最后均会调用最后一项重载函数,因此在此我们分析最后一个重载函数。在此之前,先列出一些LayoutInflater中定义的标签常量:
1 | private static final String TAG_MERGE = "merge"; |
重载的解析函数:
1 | public View inflate(XmlPullParser parser, ViewGroup root, boolean attachToRoot) { |
代码标有注释,一路过来应该不难看懂。在此我们不分析特殊的标签解析,因此我们的代码应该一路执行至第42行,调用了createViewFromTag方法:
1 | View createViewFromTag(View parent, String name, AttributeSet attrs) { |
该方法有多处调用了onCreateView或createView来生成解析的顶层View,onCreateView方法最终会调用createView方法,因此我们一起来看看createView方法:
1 | public final View createView(String name, String prefix, AttributeSet attrs) |
适当添加了注释,代码并不难看懂,主要是通过Java的反射机制实例化了对应的View,并通过缓存View的构造函数提高实例化速度。
回到我们的inflate方法,第47行判断我们传入的root(即父View)是否为空,若不为空则生成对应的测量标准(因此当我们解析一个布局的时候一定要传入对应的父View,否则无法生成正确的测量标准将导致解析出来的布局大小不正确)。
再继续往下执行,在第59行代码调用了rInflate方法开始解析我们的布局顶层View的子View:
1 | void rInflate(XmlPullParser parser, View parent, final AttributeSet attrs, |
有了注释该方法并不难懂,该方法会一直迭代调用自身直到xml文件解析完毕,是一个挺耗时的过程。
回到我们的inflate方法,在第63行,我们判断root是否为空,若不为空且我们设定了布局需要绑定到父View(attachToRoot == true),那么我们的布局就会添加到父View中,并最终解析的返回结果为父View(第70行);若为空或不绑定,则返回的结果为我们需要解析的布局的顶层View。
以下为LayoutInflater#inflate工作流程图: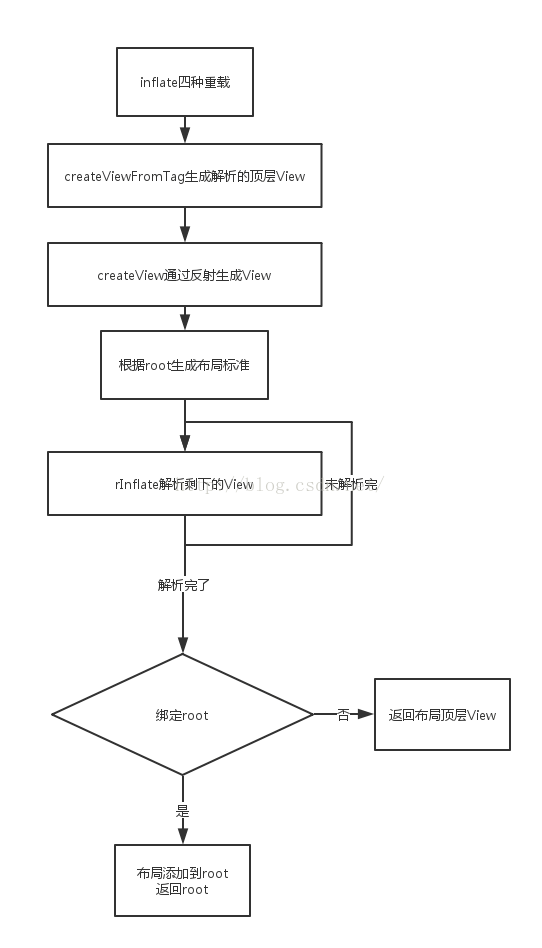
总而言之,当我们使用inflate方法的时候,一定要记得加入root参数,这样我们解析的布局文件大小才能正确无误,要是希望布局文件解析完后添加到root中,只需把attachToRoot设为true即可。